Refactoring Firefox’s Encrypted Stream (DecryptingInputStream)
TL;DR
- Refactored DecryptingInputStream::{Available,Seek} to reduce self-Tell/Seek and make state handling easier to reason about.
- The reason of refactor was that repeatedly called Self-Tell/Seek caused complexity and potentially spurious I/O (see Bugzilla discussion).
- Available() now uses cached decrypted size; Seek() avoids unnecessary work when staying within the current block.
Background
Firefox has encrypted stream mechanism. You can see it's used for example in IDB on PBM (Private Browsing Mode). PBM basically tries not to leave trails. For example, QuotaManager tries to remove files at the end of the session. Nonetheless, encryption is a good defensive approach for the failure of cleanup.
I refactored decryption logic of the encrypted stream. The bug ticket is Bug 2016957. And the followings are the patches :)
Make EnsureDecryptedStreamSize not to change the state. r?jari
Clean up DecryptingInputStream::Available. r?jari
Clean up DecryptingInputStream::Seek. r?jari
So today I'd like to explain how it works and what I did :)
How encrypted stream works
It consists of the two primitive streams, DecryptingInputStream and EncryptingOutputStream. Obviously, they correspond to I/O. The latter encrypts the output, i.e. data written out by Firefox. The former decrypts it.
// Paired with DecryptingInputStream which can be used to read the data written
// to the underlying stream, using the same (or more generally, a compatible)
// CipherStrategy, when created with the same key (assuming a symmetric cipher
// is being used; in principle, an asymmetric cipher would probably also work).
template <typename CipherStrategy>
class EncryptingOutputStream final : public EncryptingOutputStreamBase {
Write (EncryptingOutputStream)
EncryptingOutputStream cuts the data into segments, encrypts them with the specific algorithm (this post doesn't dig into that) and compounds each of them with the metadata with data size and nonce.
In summary, EncryptingOutputStream converts data into a series of encrypted block that have the following format.
// An encrypted block has the following format:
// - one basic block containing a uint16_t stating the actual payload length
// - one basic block containing the cipher prefix (tyipically a nonce)
// - encrypted payload up to the remainder of the specified overall size
[ Size | IV | Encrypted Data ]
The strategy is like this.
- accumulate data to a buffer called mBuffer.
- when the size of accumulated data in the buffer reaches the max payload size, encrypt the data and write it out to another buffer called mEncryptedBlock with the encryption-related meta data.
- flush mEncryptedBlock to the base stream (mBaseStream).
- return 1.
- Because the size of the original data is not necessarily multiple of the max payload size, the leftover may come up. This is padded and processed, mainly when the stream itself is closed.
Here is the more detailed explanation with an AA like phrack :)
.-----------------------------------------------------------.
| STEP 1: Buffering Plain Data |
| - Data is read from aReader into mBuffer. |
| - mNextByte tracks the amount of data buffered. |
'-----------------------------------------------------------'
[ the original data ] aReader
|
| reads incoming data stream
v
[ incoming data | free ] mBuffer
|------------------>|
mNextByte
.-----------------------------------------------------------.
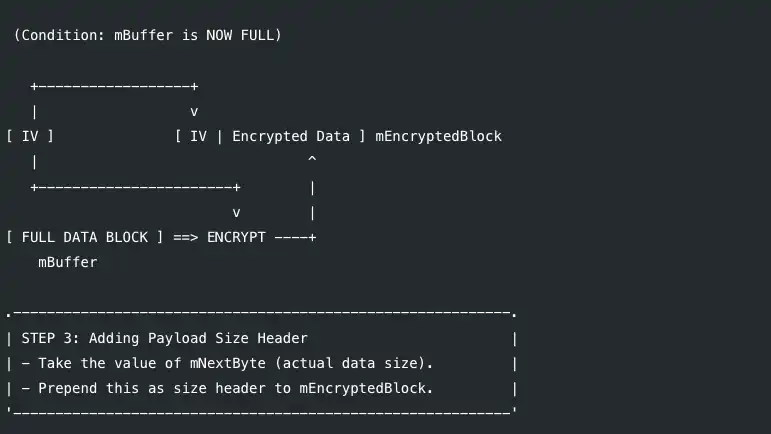
| STEP 2: Encryption & IV Handling (Trigger: Buffer Full) |
| - When mBuffer is full, generate an IV. |
| - Encrypt the data. |
| - Copy [ IV + Encrypted Data ] into mEncryptedBlock. |
'-----------------------------------------------------------'
(Condition: mBuffer is NOW FULL)
+------------------+
| v
[ IV ] [ IV | Encrypted Data ] mEncryptedBlock
| ^
+-----------------------+ |
v |
[ FULL DATA BLOCK ] ==> ENCRYPT ----+
mBuffer
.-----------------------------------------------------------.
| STEP 3: Adding Payload Size Header |
| - Take the value of mNextByte (actual data size). |
| - Prepend this as size header to mEncryptedBlock. |
'-----------------------------------------------------------'
mNextByte (is equal to the size of data!)
|
| prepended as size
v
[ Size | IV | Encrypted Data ] mEncryptedBlock
(Final Packet Layout)
.-----------------------------------------------------------.
| STEP 4: Flushing to Output Stream |
| - Write the whole mEncryptedBlock to mBaseStream. |
'-----------------------------------------------------------'
[ Size | IV | Encrypted Data ] mEncryptedBlock
|
| written to underlying stream
v
[ SINK ] mBaseStream
Eventually, SINK gets like this.
[[ Size | IV | Encrypted Data ][ Size | IV | Encrypted Data ][ Size | IV | Encrypted Data ]...]
The definition of the member vars are here.
template <typename CipherStrategy>
class EncryptingOutputStream final : public EncryptingOutputStreamBase {
[...]
private:
[...]
CipherStrategy mCipherStrategy;
// Buffer holding copied plain data. This must be copied here
// so that the encryption can be performed on a single flat buffer.
// XXX This is only necessary if the data written doesn't contain a portion of
// effective block size at a block boundary.
nsTArray<uint8_t> mBuffer;
nsCOMPtr<nsIRandomGenerator> mRandomGenerator;
// The next byte in the plain data to copy incoming data to.
size_t mNextByte = 0;
// Buffer holding the resulting encrypted data.
using EncryptedBlockType = EncryptedBlock<CipherStrategy::BlockPrefixLength,
CipherStrategy::BasicBlockSize>;
Maybe<EncryptedBlockType> mEncryptedBlock;
The operation is processed mainly by these three methods:
- WriteSegments: accumulate data to mBuffer and exec FlushToBaseStream every time mBuffer is filled
- FlushToBaseStream: encrypt mBuffer and write it out to mBaseStream
- Close: close the stream after writing the rest plain buffer out to mBaseStream
With the explanation above, I think it's not so difficult to understand how EncryptingOutputStream works. You can see the relevant code from the below links.
The caveat is the padding in FlushToBaseStream. You'll find that this padding happens only for the final encryption block. The reason why the padding is limited to the last block is because it wants to keep the simplicity of position calculation when decrypting the stream. I'm gonna explain that later.
if (mNextByte < mEncryptedBlock->MaxPayloadLength()) {
if (!mRandomGenerator) {
mRandomGenerator =
do_GetService("@mozilla.org/security/random-generator;1");
if (NS_WARN_IF(!mRandomGenerator)) {
return NS_ERROR_FAILURE;
}
}
const auto payload = mEncryptedBlock->MutablePayload();
const auto unusedPayload = payload.From(mNextByte);
nsresult rv = mRandomGenerator->GenerateRandomBytesInto(
unusedPayload.Elements(), unusedPayload.Length());
if (NS_WARN_IF(NS_FAILED(rv))) {
return rv;
}
}
Read (DecryptingInputStream)
DecryptingInputStream provides methods not just for read, but also for various operations like Tell/Seek.
The image is: on the input stream, we have a cursor. We can know its position by Tell and move it to the arbitrary position by Seek.
Stream: [...data...data...bluh...bluh...]
| ^
| |
|<--- Offset -->|
(e.g. 24)
-> Tell() returns 24
===========================================
1. Original Position (e.g. 24):
[...data...data...bluh...bluh...]
^
2. EXECUTE: Seek(50)
[...data...data...bluh...bluh...]
^
New Position
FYI, Tell and Seek are typical operations on stream. You can google the words like "stream seek tell" and find various programming languages and platforms come up there.
What I had to do was cleaning up these logics. So let me explain them as of before the refactor.
Please keep in mind that DecryptingInputStream is constructed on the base stream. The base stream has the original encrypted data. DecryptingInputStream has this stream as a member and realize the decrypted stream using other states and buffers.
ReadSegments and ParseNextChunk
These methods are for reading the encrypted data.
The process is very similar to WriteSegments. The point here is, when decrypting data, data is loaded by the chunk of metadata and encrypted data. So how much of mBaseStream is loaded is always a multiple of the chunk size. This is an invariant.
mBaseStream
[[ Size | IV | Encrypted Data ][ Size | IV | Encrypted Data ][ Size | IV | Encrypted Data ]...]
|<-----load this chunk------>||<---next, load this chunk-->||<--then, load this chunk--->|...
It improves simplicity of calculation that each chunk's size is the same. (Of course, there might be trade offs in terms of encryption safety.)
Decrypted data is stored into a buffer called mPlainBuffer. mNextByte manages how much is read in mPlainBuffer and mPlainBytes is equal to the size of data loaded into mPlainBuffer. It's important to distinguish being loaded on mPlainBuffer and being read. ReadSegments receives how much you wanna read the stream and if this arg is not a multiple of the encrypted block size, the overleft will happen. But even in that case, how much of mBaseStream is loaded is always a multiple of the chunk size.
mBaseStream (Encrypted Chunks)
[[ Chunk 0 ][ Chunk 1 ][ Chunk 2 ][ Chunk 3 ] ... ]
^
The cursor is at the end of Chunk 1
========== at the same time =======================
mPlainBuffer
[ Decrypted Chunk 1 ]
|--------->| mNextByte
|------------------>| mPlainByte
Tell
Tell has to return the cursor position on the decrypted clear, not simply on the encrypted data. Let's see it.
template <typename CipherStrategy>
NS_IMETHODIMP DecryptingInputStream<CipherStrategy>::Tell(
int64_t* const aRetval) {
MOZ_ASSERT(aRetval);
if (!mBaseStream) {
return NS_BASE_STREAM_CLOSED;
}
if (!EnsureBuffers()) {
return NS_ERROR_OUT_OF_MEMORY;
}
int64_t basePosition;
nsresult rv = (*mBaseSeekableStream)->Tell(&basePosition);
if (NS_WARN_IF(NS_FAILED(rv))) {
return rv;
}
if (basePosition == 0) {
*aRetval = 0;
return NS_OK;
}
MOZ_ASSERT(0 == basePosition % *mBlockSize); // [1]
const auto fullBlocks = basePosition / *mBlockSize;
MOZ_ASSERT(fullBlocks);
*aRetval = (fullBlocks - 1) * mEncryptedBlock->MaxPayloadLength() + mNextByte; // [2]
return NS_OK;
}
[1] makes sure that the aforementioned invariant, "how much of mBaseStream is loaded is always a multiple of the chunk size". As explained before, mNextByte is how much of mBaseStream is read. So, the current cursor position is equal to (the num of loaded chunks - 1) * payload size + mNextByte. This is the logic behind [2].
Example: base stream's cursor is at the start of Chunk 3
(= at the end of Chunk 2)
mBaseStream
[ Chunk 0 ][ Chunk 1 ][ Chunk 2 ] | [ Chunk 3 ]...
|<------- Fully Read ---------->| ^ (basePosition)
-> basePosition / BlockSize = 3
mPlainBuffer
[ Decrypted Chunk 2 ]
|--------->| mNextByte
|------------------>| mPlainByte
-> the current position on the clear = (3 - 1) * chunk length + mNextByte
Seek
Seek's code is long. So let's focus on the interesting points.
template <typename CipherStrategy>
NS_IMETHODIMP DecryptingInputStream<CipherStrategy>::Seek(const int32_t aWhence,
int64_t aOffset) {
[...]
int64_t baseBlocksOffset;
int64_t nextByteOffset;
switch (aWhence) {
case NS_SEEK_CUR:
// XXX Simplify this without using Tell.
aOffset += current;
break;
case NS_SEEK_SET:
break;
case NS_SEEK_END:
// XXX Simplify this without using Seek/Tell.
aOffset += *mDecryptedStreamSize;
break;
default:
return NS_ERROR_ILLEGAL_VALUE;
}
if (aOffset < 0 || aOffset > *mDecryptedStreamSize) {
return NS_ERROR_ILLEGAL_VALUE;
}
baseBlocksOffset = aOffset / mEncryptedBlock->MaxPayloadLength();
nextByteOffset = aOffset % mEncryptedBlock->MaxPayloadLength();
// XXX If we remain in the same block as before, we can skip this.
rv =
(*mBaseSeekableStream)->Seek(NS_SEEK_SET, baseBlocksOffset * *mBlockSize);
if (NS_WARN_IF(NS_FAILED(rv))) {
return rv;
}
uint32_t readBytes;
rv = ParseNextChunk(true /* aCheckAvailableBytes */, &readBytes);
if (NS_WARN_IF(NS_FAILED(rv))) {
return rv;
}
if (readBytes == 0 && baseBlocksOffset != 0) {
mPlainBytes = mEncryptedBlock->MaxPayloadLength();
mNextByte = mEncryptedBlock->MaxPayloadLength();
} else {
mPlainBytes = readBytes;
mNextByte = nextByteOffset;
}
autoRestorePreviousState.release();
return NS_OK;
}
First of all, Seek receives two args: aWhence and aOffset. aWhence is an enum and has the three patterns: NS_SEEK_CUR, NS_SEEK_SET and NS_SEEK_END. You can see how different they are in the switch clause.
After normalizing aOffset, aOffset is converted to blocks and an overleft. First move the cursor to the end of the encrypted block just before the one which has the position seeked. Then decrypted and load the next chunk by calling ParseNextChunk and tweak the states.
It's a trick to pinpoint the block which has a desired position without decrypting all the blocks before that. This can be done, because all the encrypted blocks other than the last one in the original stream are filled by the data, i.e. not padded at all. The restriction that only the last block can be padded makes the decryption simpler in such a way.
Available
Available tells you how much data is left based on the current position of the cursor.
template <typename CipherStrategy>
NS_IMETHODIMP DecryptingInputStream<CipherStrategy>::Available(
uint64_t* aLengthOut) {
if (!mBaseStream) {
return NS_BASE_STREAM_CLOSED;
}
int64_t oldPos, endPos;
nsresult rv = Tell(&oldPos);
if (NS_WARN_IF(NS_FAILED(rv))) {
return rv;
}
rv = Seek(SEEK_END, 0);
if (NS_WARN_IF(NS_FAILED(rv))) {
return rv;
}
rv = Tell(&endPos);
if (NS_WARN_IF(NS_FAILED(rv))) {
return rv;
}
rv = Seek(SEEK_SET, oldPos);
if (NS_WARN_IF(NS_FAILED(rv))) {
return rv;
}
*aLengthOut = endPos - oldPos;
return NS_OK;
}
Available first records the current cursor position. Then it moves the cursor to the end of the stream and records the position. Because Tell returns the position based on the decrypted clear, the result of subtraction is equal to how much is left.
Refactor
The problem was said to that they repeatedly self-Tell and self-Seek. This had made the code complex and possibly led to unnecessary I/O.
The current decrypting stream really likes to use Tell/Seek on the underlying stream and itself and this makes the code more complex and harder to reason about than I think is helpful in addition to the potential spurious I/O. (There are also 3 XXX comments in the code relating to this area from the original author.) For example, mozilla::dom::quota::DecryptingInputStream::Available performs 2 self-tells and 2 self-seeks (as in on the decrypting stream, not on the underlying stream), and then mozilla::dom::quota::DecryptingInputStream::Seek also does a self-tell.
https://bugzilla.mozilla.org/show_bug.cgi?id=1975760
That's why I refactored Seek and Available.
Available
DecryptingInputStream has a convenient method called EnsureDecryptedStreamSize. As you can guess, this calculates the size of the entire clear. So I used it in Available and reduced Tell and Seek.
The below is the refactored code.
template <typename CipherStrategy>
NS_IMETHODIMP DecryptingInputStream<CipherStrategy>::Available(
uint64_t* aLengthOut) {
if (!mBaseStream) {
return NS_BASE_STREAM_CLOSED;
}
int64_t current;
nsresult rv = Tell(¤t);
if (NS_WARN_IF(NS_FAILED(rv))) {
return rv;
}
rv = EnsureDecryptedStreamSize();
if (NS_WARN_IF(NS_FAILED(rv))) {
return rv;
}
auto length = CheckedUint64(*mDecryptedStreamSize) - current;
if (!length.isValid()) {
return nsresult::NS_ERROR_ILLEGAL_VALUE;
}
*aLengthOut = length.value();
return NS_OK;
}
EnsureDecryptedStreamSize is a bit costly, but its result is cached. So the subsequent calls are almost zero cost. Available's cost has been reduced to the one-time costly calculation and Tell from two Seeks and two Tells :)
Seek
How I refactored Seek is summarized to the two points.
One is replacing the self-Tell after getting the base stream's position with a calculation using the block size.
before
int64_t baseCurrent;
nsresult rv = (*mBaseSeekableStream)->Tell(&baseCurrent);
[...]
int64_t current;
rv = Tell(¤t);
after
int64_t baseCurrent;
nsresult rv = (*mBaseSeekableStream)->Tell(&baseCurrent);
[...]
int64_t current = 0;
if (baseCurrent > 0) {
// The underlying stream is always written in fixed-size units (mBlockSize)
// with padding, according to the flush implementation of
// EncryptedOutputStream. And baseCurrent always points to the end of the
// current block in our buffer, according to ParseNextChunk and Seek. That
// means baseCurrent is always a multiple of mBlockSize.
MOZ_DIAGNOSTIC_ASSERT(
std::has_single_bit(*mBlockSize) &&
(0 == (static_cast<size_t>(baseCurrent) & (*mBlockSize - 1))));
// Thus, (baseCurrent / *mBlockSize - 1) gives the number of preceding
// blocks. We multiply this by MaxPayloadLength() and add mNextByte to
// arrive at the current logical position.
current =
(baseCurrent / *mBlockSize - 1) * mEncryptedBlock->MaxPayloadLength() +
mNextByte;
}
Because mBlockSize is a power of two, the division by mBlockSize can be written in this way. This is cheaper than baseCurent % mBlockSize. I didn't know this and it's clever, isn't it? :)
std::has_single_bit(*mBlockSize) &&
(0 == (static_cast<size_t>(baseCurrent) & (*mBlockSize - 1)))
The other point is I added an early return for cases where the target offset is in the current block.
// If the target offset is in the current block, it is enough to move
// mNextByte.
int64_t blockStart = current - mNextByte;
if (blockStart <= aOffset &&
aOffset <= blockStart + static_cast<int64_t>(mPlainBytes)) {
mNextByte += aOffset - current;
return NS_OK;
}
Outro
This is a brief explanation of how the encrypted stream in Firefox works and how I refactored it.
What's the next topic? Please look forward to the post, thanks :)